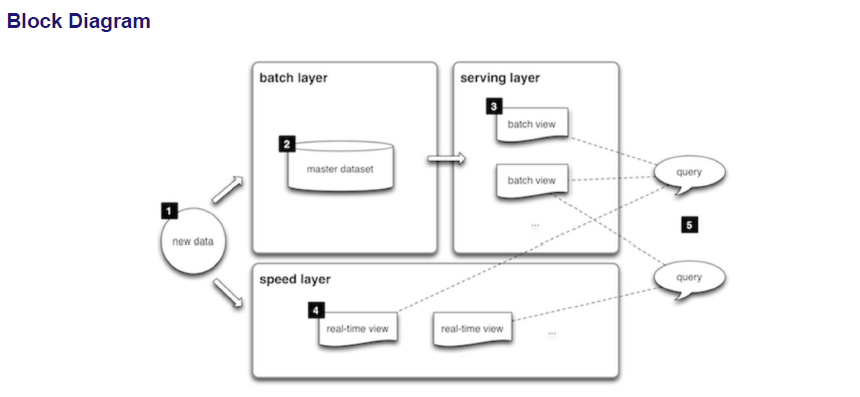
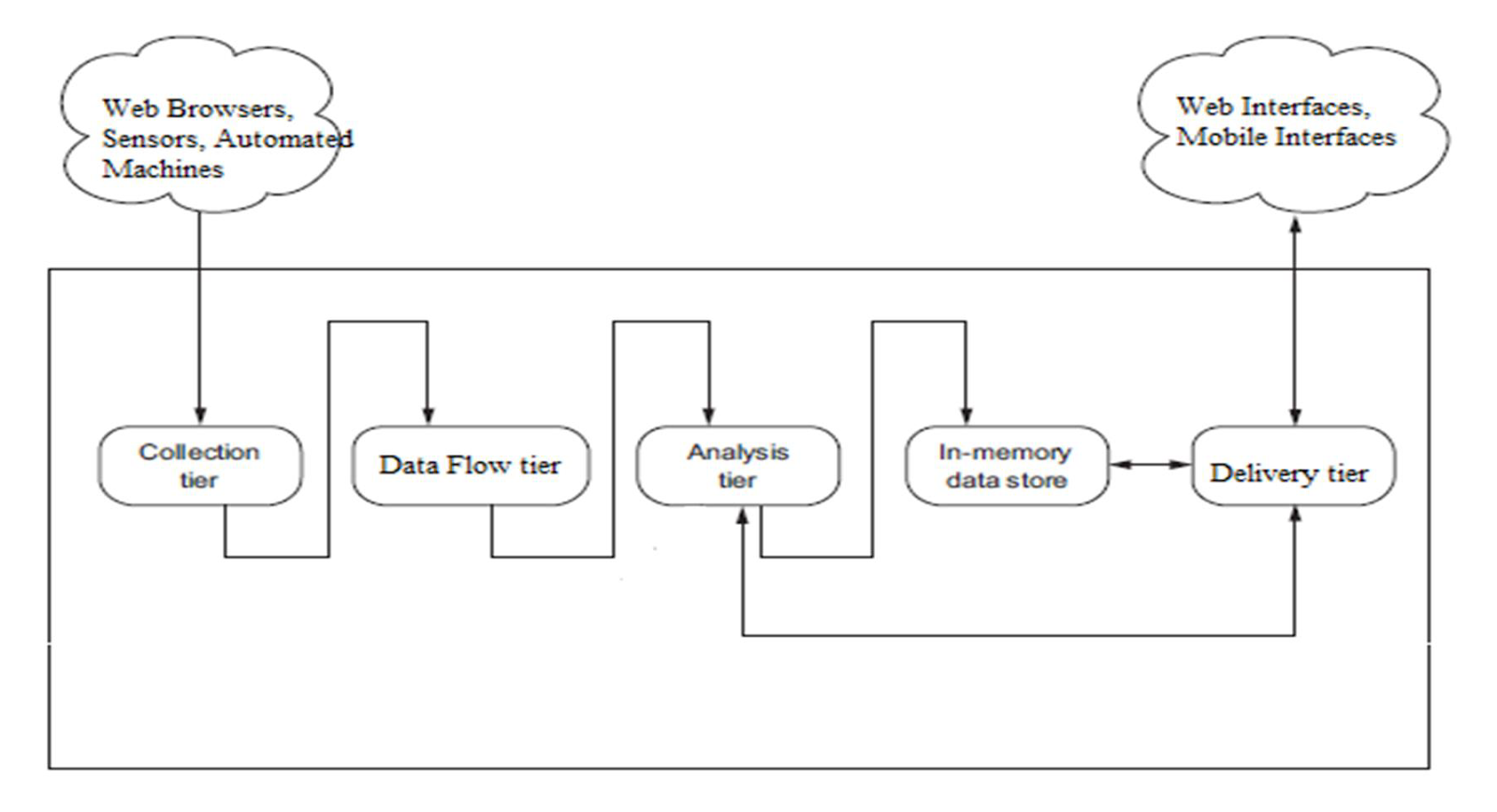
Streaming Data System Architecture Components
• Collection
• Data Flow
• Processing
• Storage
• Delivery
Collection System
• Mostly communication over TCP/IP network using HTTP
• Websites log data was the initial days use case
• W3C standard log data format was used
• Newer formats like JSON, AVRO, Thrift are available now
• Collection happens at specialized servers called edge servers
• Collection process is usually application specific
• New servers integrates directly with data flow systems
• Old servers may or may not integrate directly with data flow systems
Data Flow Tier
• Separation between collection tier and processing layer is required
• Rates at which these systems works are different
• What if one of system is not able to cope with another system?
• Required intermediate layer that takes responsibility of
• accepting messages / events from collection layer
• providing those messages / events to processing layer
• Real time interface to data layer for both producers and consumers of data
• Helps in guaranteeing the “at least once” semantics
Processing / Analytics Tier
• Based on “data locality” principle
• Move the software / code to a the location of data
• Rely on distributed processing of data
• Framework does the most of the heavy lifting of data partitioning, job scheduling, job managing
• Available Frameworks
• Apache Storm
• Apache Spark (Streaming)
• Apache Kafka Streaming etc
Storage Tier
In memory or permanent
• Usually in memory as data is processed once
• But can have use cases where events / outcomes needs to be persisted as well
• NoSQL databases becoming popular choice for permanent storage
• MongoDB
• Cassandra
• But usage varies as per the use case, still no database that fits all use cases
Delivery Layer
• Usually web based interface
• Now a days mobile interfaces are becoming quite popular
• Dashboards are built with streaming visualizations that gets continuously updated as
underlying events are processed
• HTML + CSS + Java script + Websockets can be used to create interfaces and update
them
• HTML5 elements can be used to render interfaces
• SVG, PDF formats used to render the outcomes
• Monitoring / Alerting Use cases
• Feeding data to downstream applications
----------------------------------------------------------------------------
All the messages below are just forwarded messages if some one feels hurt about it please add your comments we will remove the post.Host/author is not responsible for these posts.