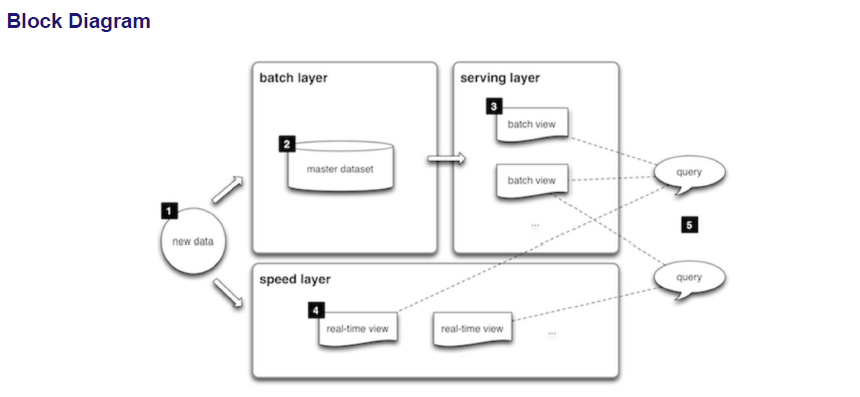
Basic Flow of Events Of Lamda Architecture
All data entering the system is dispatched to both the batch layer and the speed layer for
processing.
2. The batch layer has two functions:
(i) managing the master dataset (an immutable, append-only set of raw data)
(ii) to pre-compute the batch views.
3. The serving layer indexes the batch views so that they can be queried in low-latency, ad-hoc
way.
4. The speed layer compensates for the high latency of updates to the serving layer and deals
with recent data only.
5. Any incoming query can be answered by merging results from batch views and real-time views
Batch Layer
New data comes continuously, as a feed to the data system.
• It gets fed to the batch layer and the speed layer simultaneously.
• It looks at all the data at once and eventually corrects the data in the stream layer.
• Here we can find lots of ETL and a traditional data warehouse.
• This layer is built using a predefined schedule, usually once or twice a day.
• The batch layer has two very important functions:
• To manage the master dataset
• To pre-compute the batch views.
Speed Layer (Stream Layer)
• This layer handles the data that are not already delivered in the batch view due to the latency of
the batch layer.
• In addition, it only deals with recent data in order to provide a complete view of the data to the
user by creating real-time views.
• Speed layer provides the outputs on the basis enrichment process and supports the serving
layer to reduce the latency in responding the queries.
• As obvious from its name the speed layer has low latency because it deals with the real time
data only and has less computational load.
Serving Layer
• The outputs from batch layer in the form of batch views and from speed layer in the form of
near-real time views are forwarded to the serving layer.
• This layer indexes the batch views so that they can be queried in low-latency on an ad-hoc
basis.
Pros
• Batch layer of Lambda architecture manages historical data with the fault tolerant
distributed storage which ensures low possibility of errors even if the system crashes.
• It is a good balance of speed and reliability.
• Fault tolerant and scalable architecture for data processing.
Cons
• It can result in coding overhead due to involvement of comprehensive processing.
• Re-processes every batch cycle which is not beneficial in certain scenarios.
• A data modelled with Lambda architecture is difficult to migrate or reorganize.
All the messages
below are just forwarded messages if some one feels hurt about it please add your comments we will remove the post.Host/author is not responsible for these posts.
No comments:
Post a Comment