Search engine
1. Crawler Based
2. Directory
3. Metasearch
Search Types
1. General Search / Horizontal Search : ex : google --> results are very broad and results might not be relevant sometimes.
2. Vertical search - very specific search or specific part of internet ; ex: google images / Amazon product search.
Web challenges for IR
---------------------
1.Distributed Data: Documents spread over millions of different web servers.
2.Volatile Data: Many documents change or disappear rapidly (e.g. dead links).
3.Large Volume: Billions of separate documents.
4.Unstructured and Redundant Data: No uniform structure, HTML errors, up to 30% (near) duplicate documents.
5.Quality of Data: No editorial control, false information, poor quality writing, typos, etc.
6.Heterogeneous Data: Multiple media types (images, video, VRML), languages, character sets, etc.
Modeling the Web
----------------
Heaps’ and Zipf’s laws are also valid in the Web.
»In particular, the vocabulary grows faster (larger) and the word
distribution should be more biased (larger)
Heaps’ Law
» An empirical rule which describes the vocabulary growth as a function of the text size.
» It establishes that a text of n words has a vocabulary of size O(n𝛽) for
0< 𝛽 <1
Zipf’s Law
» An empirical rule that describes the frequency of the text words.
» It states that the i-th most frequent word appears as many times as
the most frequent one divided by i 𝛽, for some 𝛽 >1
Different types of queries
1. Informational queries : learn about something - 40%
2. Navigational queries : take to a page - 25%
3. Transactional queries : want to do something - 35%
Essential Characteristics for user-friendliness of a website
1.Mobile Compatibility
2.Accessible to All Users
3.Well Planned Information Architecture
4.Well-Formatted Content That Is Easy to Scan
5.Fast Load Times
6.Browser Consistency
7.Effective Navigation
8.Good Error Handling
9.Contrasting Color Scheme
10.Usable forms
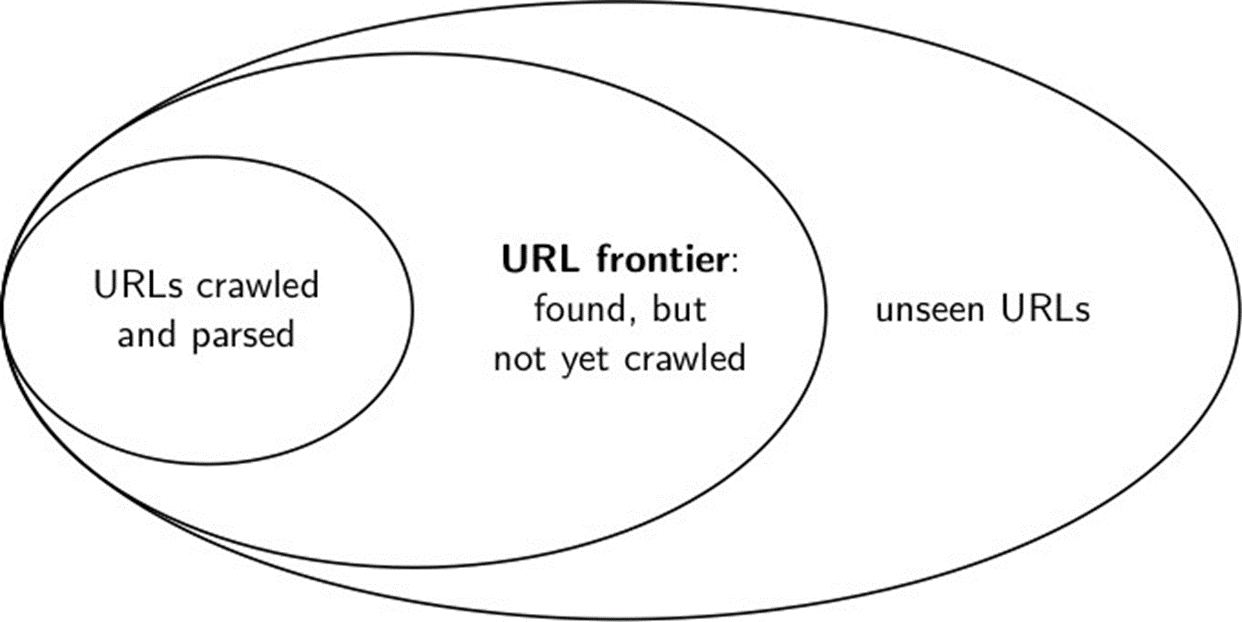
Centralized Architecture - Crawler-Indexer Architecture
important components
1.Crawler / spider
2.Indexer
3.Query Engine
Indexing process
1. text acquisition
2. text transformation
3. Index creation
1.User Interaction
2.Ranking
3.Evaluations
Distributed Architecture -
Harvest
Gathers and Brokers
User Interface
query interface
Answer interface
----------------------------------------------------------------------------
All the messages below are just forwarded messages if some one feels hurt about it please add your comments we will remove the post. Host/author is not responsible for these posts.