
All the messages below are just forwarded messages if some one feels hurt about it please add your comments we will remove the post. Host/author is not responsible for these posts.





Q1. Discuss briefly 3 key issues that will impact the
performance of a data parallel application and need careful optimization.
Q2. The CPU
of a movie streaming server has L1 cache reference of 0.5 ns and main memory
reference of 100 ns. The L1 cache hit during peak hours was found to be
23% of the total memory references. [Marks: 4]
Q3. A travel review site stores (user, hotel, review)
tuples in a data store. E.g. tuple is (“user1”, “hotel ABC”, “<review>”).
The data analysis team wants to know which user has written the most reviews
and the hotel that has been reviewed the most. Write MapReduce pseudo-code to
answer this question. [Marks: 4]
Q4. An e-commerce site stores (user, product, rating)
tuples for data analysis. E.g. tuple is (“user1”, “product_x”, 3), where rating
is from 1-10 with 10 being the best. A user can rate many products and products
can be rated by many users. Write MapReduce pseudo-code to find the range (min
and max) of ratings received for each product. So each output record contains
(<product>, <min rating> to <max rating>).
[Marks: 4]
Q5. Name a system and explain how it utilises the
concepts of data and tree parallelism.
[Marks: 3]
Q6. An
enterprise application consists of a 2 node active-active application server
cluster connected to a 2 node active-passive database (DB) cluster. Both tiers
need to be working for the system to be available. Over a long period of time
it has been observed that an application server node fails every 100 days and a
DB server node fails every 50 days. A passive DB node takes 12 hours to
take over from the failed active node. Answer the following questions.
[Marks: 4]
Q7. In the
following application scenarios, point out what is most important - consistency
or availability, when a system failure results in a network partition in the
backend distributed DB. Explain briefly the reason behind your answer.
[Marks: 4]
(a)
A limited quantity discount offer on a product for 100 items at an online
retail store is almost 98% claimed. (b) An online survey application records
inputs from millions of users across the globe.
(c) A travel reservation website is trying to sell rooms at a destination that
is seeing very few bookings.
(d) A multi-player game with virtual avatars and users from all across the
world needs a set of sequential steps between team members to progress across
game milestones.
Q8. Assume
that you have a NoSQL database with 3 nodes and a configurable replication
factor (RF). R is the number of replicas that participate to return a Read
request. W is the number of replicas that need to be updated to acknowledge a
Write request. In each of the cases below explain why data is consistent or
in-consistent for read requests.
[Marks: 4]
1.
RF=1, R=1, W=1.
2. RF=2, R=1, W=Majority/Quorum.
3. RF=3, R=2, W=Majority/Quorum.
4. RF=3, R=Majority/Quorum, W=3.
Birla Institute of Technology & Science, Pilani
Work Integrated Learning Programmes Division
Second Semester 2020-2021
Comprehensive Examination
(EC-3 Make-up)
Course No. : DSECL ZG556
Course Title : STREAM PROCESSING AND ANALYTICS
Nature of Exam : Open Book
Weightage : 45%
Duration : 2 Hours
Date of Exam : 11-09-2021 FN
Note to Students:
Please follow all the Instructions to Candidates given on the cover page of the answer book.
All parts of a question should be answered consecutively. Each answer should start from a fresh page.
Assumptions made if any, should be stated clearly at the beginning of your answer.
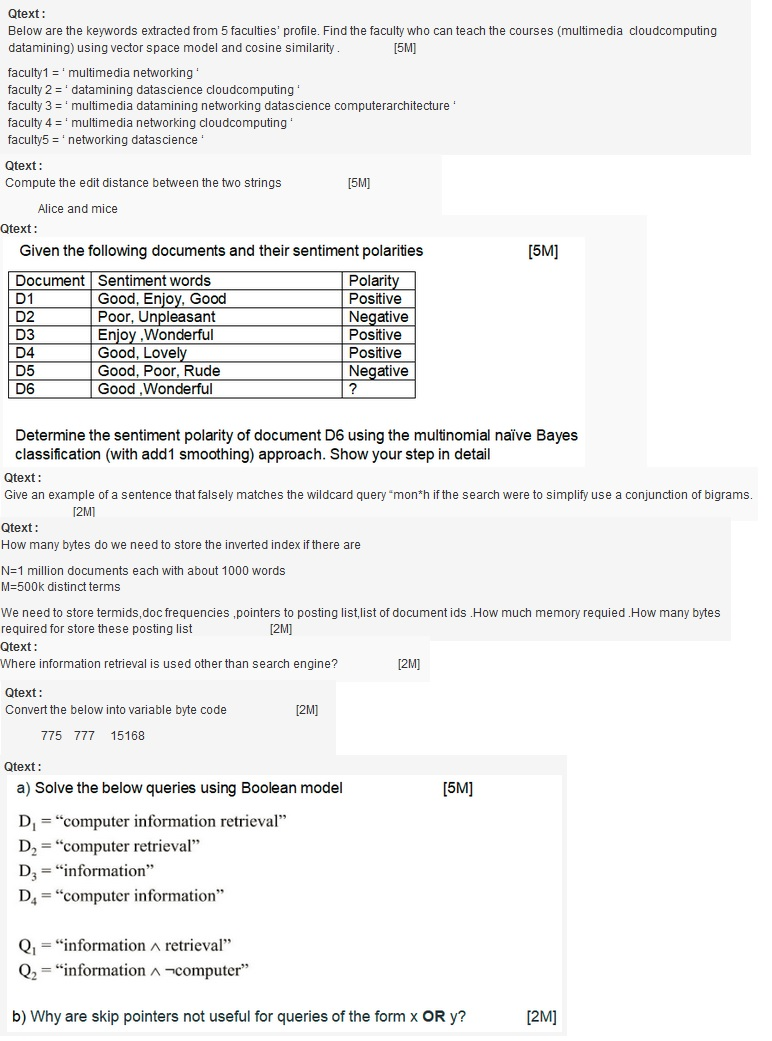
Q1. Every day a multinational online taxi dispatch company gathers terabytes of event data from its mobile users. By using Kafka, Spark Streaming, and HDFS, to build a continuous ETL pipeline, they can convert raw unstructured event data into structured data as it is collected, and then use it for further and more complex analytics. [5 + 5 = 10]
With this scenario in mind, explain how Spark Streaming will be leveraged as solution using a nicely labelled architecture diagram?
List and briefly explain the Apache Spark API's that can be used in?
Q.2. Consider the following Kafka Cluster description.
10 node cluster
Name of the Topic: Cluster
Number of Partitions: 4
The Replication factor of ‘Bus: 3
7 producers
5 consumers
Draw Kafka’s architecture clearly highlighting the following in a block diagram
-producers, consumers, broker, topic and partitions.
How many consumer groups can be created for this configuration?
What is the maximum number of consumers that each consumer group can have while ensuring maximum parallelism?
What is the maximum number of server failures that this setup can handle?
[2 + 1 + 1 + 1 = 5]
Q.3. Explain the various components available in the Apache Flink with suitable real time example.
[10]
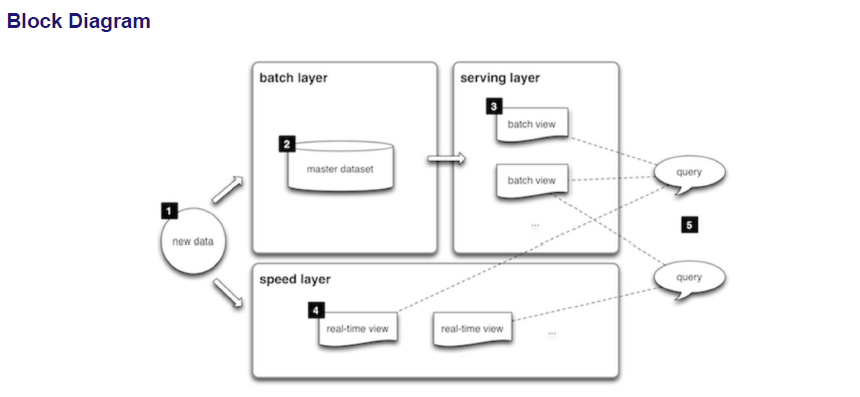
Q4. Consider an online ecommerce portal where customers can search for the products anonymously but for placing the order, they need to have the account with the provider. When customers are browsing the products on the portal, their online behavior is getting monitored by the provider. The provider has business relationship with another online movie service provider whose movies are also displayed and sold on the provider’s platform. Also the users search queries are shared between these providers. The search queries are also matched with the users profile to provide product / movie recommendations to the users. For this purpose it makes use of Apache Storm as streaming platform. With the help of suitable architectural diagram, represent how this recommendation activity can be carried out. [8]
Q5. Consider the following streaming SQL query where an output record (or row) is generated specifying the updates to the minimum and maximum temperatures over the window W1, plus an incrementally updated average for the temperature over that period. [3 * 4 = 12]
SELECT STREAM
MIN(TEMP) OVER W1 AS WMIN_TEMP,
MAX(TEMP) OVER W1 AS WMAX_TEMP,
AVG(TEMP) OVER W1 AS WAVG_TEMP
FROM WEATHERSTREAM
WINDOW W1
Let’s assume that input streaming weather stream has following temperature values coming in at regular interval of two minutes:
{12, 14, 15, 13, 16, 20}
What will be the output of the above query (with proper explanation) if
Window is defined as sliding window of length 3
Window is defined as batch window of length 3
Window is defined as sliding window of time 4 minutes
Window is defined as batch window of time 3 minutes



Hit + Miss = Total CPU ReferenceHit Ratio h = Hit / ( Hit + Miss )
Tavg = Average time to access memoryTavg = h * Tc + ( 1-h ) * ( Tm + Tc )



The tf-idf (term frequency-inverse document frequency) is a measure of the importance of a word in a document or a collection of documents. It is commonly used in information retrieval and natural language processing tasks.
The formula for calculating tf-idf is:
tf-idf = tf * idf
where:
tf (term frequency) is the frequency of the word in the document. It can be calculated as the number of times the word appears in the document divided by the total number of words in the document.
idf (inverse document frequency) is a measure of the rarity of the word. It can be calculated as the logarithm of the total number of documents divided by the number of documents that contain the word.
The resulting tf-idf score for a word reflects both the importance of the word in the specific document and its rarity in the collection of documents. Words that are common across all documents will have a lower tf-idf score, while words that are specific to a particular document and rare in the collection will have a higher tf-idf score.
----------------------------------
The tf-idf (term frequency-inverse document frequency) is a measure of the importance of a word in a document or a collection of documents. It is commonly used in information retrieval and natural language processing tasks.
The formula for calculating tf-idf is:
tf-idf = tf * idf
where:
tf (term frequency) is the frequency of the word in the document. It can be calculated as the number of times the word appears in the document divided by the total number of words in the document.
idf (inverse document frequency) is a measure of the rarity of the word. It can be calculated as the logarithm of the total number of documents divided by the number of documents that contain the word.
The resulting tf-idf score for a word reflects both the importance of the word in the specific document and its rarity in the collection of documents. Words that are common across all documents will have a lower tf-idf score, while words that are specific to a particular document and rare in the collection will have a higher tf-idf score.
----------------------



