Birla Institute of Technology and Science, Pilani
Work Integrated Learning Programmes Division
BITS WILP Programme - M. Tech. in Data Science and Engg
I Semester 2020-2021
Mid-Semester Test
(EC2 - Makeup)
Course Number DSECL ZG523
Course Name Introduction to Data Science
Nature of Exam Open Book
Weight-age for grading 30
Duration 1.5 hrs
Date of Exam
# Pages 2
# Questions 5
Instructions
1. All questions are compulsory.
2. Questions are to be answered in the order in which they appear in this paper.
3. All answers must be directed to the question in short and simple paragraphs or bullet points;
use visuals/diagrams wherever necessary.
4. Assumptions made if any, should be stated clearly at the beginning of your answer.
1. Challenge the accuracy of the below statements (agree/disagree) with short justification.
[Answer should contain few bullet points of no more than 2 – 4 lines]. [5]
(a) For Data Collection and Pre-processing, domain Knowledge is essential, whereas for
Model Building and Evaluation it is optional. [2.5]
• Agree [0.5]
• Data Pre-processing (cleansing, outlier detection, imputation, feature engineering,
etc.) expects domain expertise (in the area of the Data/Business) so that Data
Scientist (or Domain expert) can identify relevant/irrelevant features, right techniques
for Data Imputation and take decisions regarding the validity of the source
data by performing EDA, etc. [1]
• Model building is purely technical activity where the focus is exclusively on the
choice of the model, tuning the parameters and evaluating the performance, etc.
using various tools. [1]
(b) In supervised learning, we do not need a separate Validation-set when there already
exists a Test-set. [2.5]
• Disagree [0.5]
• Validation-set is used for internal assessment of Model performance during development
and for hyper-parameter tuning. [1]
1
• Test-set is exclusively reserved for Testing the Model Performance on ‘un-seen’
data (kept locked away, not accessible to Model builder, similar to ‘Acceptance
Test’ in software engineering). [1]
2. You have started your spring cleaning activity. On day 10 you have decided that you
will clean your email inbox. During this cleaning, you noticed that you are paying around
Rs.3000/- per month against your internet bill. You want to reduce the bill amount. Assume
relevant data and state the assumprtions clearly at the beginning of your answer. [6]
(a) Identify the type of data analytics that you will use if you observed that the internet
usage has increased because of the pandemic. [1]
(b) Identify the type of data analytics that you will use if you compared the various bills
and then switched to a different plan that better suits your need. [1]
(c) Write any 4 questions that you will ask yourself, in the step 2. [4]
Solution:
(a) Descriptive analytics / EDA / exploratory [1]
(b) Prescriptive analytics [1]
(c) Any 4 questions suitable for Prescriptive analytics. [4]
i. Do you have any related requirements? If yes, what are those?
ii. What are the existing/related systems within the capability that capture/use related
information?
iii. What are the gaps?
iv. Who are the stakeholders?
v. Who will be affected by this implementation?
vi. Any Licenses/Commercials needed in case of proprietary solutions?
vii. Are there any other dependencies?
viii. Do you see any other problems/challenges?
ix. Does the client have a technology preference?
x. Does the client have limited / unlimited infrastructure?
xi. How will we measure the business impact of the final model? How will we justify
the project expense against the benefits?
xii. Is there a plan for domain expert validation?
xiii. If so, will the model be in a form that they can understand?
xiv. Is there an evaluation metric set up by the business?
xv. Is there a hold-out data (i.e. data used for validation) available?
xvi. Against what baseline or benchmark the results are compared?
xvii. Are the business costs and benefits considered into account?
3. Consider the below data set for carrying out some data science activity. There are four
columns identified by f1, f2, f3, f4,f5 ("f" means feature). In the table "NA" means "Not
Available" (or missing value). Your task as a data engineer is to obtain the missing values
using some imputation technique. The domain expert gave advice that f3 can be imputed
using mean, f4 can be imputed using median and f5 can be imputed using mean based on
the feature f2. Write the steps to be followed to obtain the missing values and re-write the
dataset with the imputed values. [6]
row f1 f2 f3 f4 f5
1 25 A 5 3 37
2 27 B NA 5 38
3 28 A 17 NA 40
4 24 NA 6 4 43
5 29 C NA 6 36
6 22 C 17 5 NA
7 23 A 5 5 NA
Solution:
(a) f2: Categorical data. Hence mode = A is used to impute row 4. [1]
(b) f3: mean of 5,17,6,5 is 32/4=8. Hence, impute rows 2 and 5 can be imputed using 8.
[1]
(c) f4: median = 5. Hence impute row 3 with median 5. [1]
(d) f5: row6 = 36 as there is only one value for C. row7 = mean of 37,40,43 = 40. [1*2=2]
(e) [1]
row f1 f2 f3 f4 f5
1 25 A 5 3 37
2 27 B 8 5 38
3 28 A 17 5 40
4 24 A 6 4 43
5 29 C 8 6 36
6 22 C 17 5 36
7 23 A 5 5 40
4. A motor insurance company was has an investigation team that investigates the claims
made. The fraud investigation team investigates up to 30% of all claims made. The company
realised that it was losing too much money due to fraudulent claims. List four ways
in which predictive data analytics could be used to help address this business problem. For
each proposed approach, describe the predictive model that will be built, how the model
will be used by the business, and how using the model will help address the original business
problem. [8]
Solution:
(a) Claim prediction – Predict the likelihood that an insurance claim is fraudulent. Assign
every newly arising claim a fraud likelihood. Those that are most likely to be fraudulent
could be flagged for investigation by the investigation team. Increase the number of
fraudulent claims detected and reduce the amount of money lost of fraud.
(b) Member prediction – Predict the propensity of member to commit fraud. Run this
is model every quarter to identify those members most likely to commit fraud. The
investigation company could take a risk mitigation action ranging from contacting the
member with some kind of warning to canceling the member’s policies. By identifying
members likelu to make fraudulent claims before they make them, the company could
save significant money.
(c) Application prediction – Predict the likelihood that a policty someone has applied for
will ultimately result in a fraudulent claim. For every new application this model could
be run and reject those applications that are predicted likelu to resiult in a fraudulent
claim.
(d) Payment prediction – Predict the amount most likely to be paid out by the company
after investigating the claim. Run this model, whenever new caims are made. The
policy holder could be offered the amount predicted by the model as settlement as
an alternative to goind through a claims investigating process. The company could
save on claims investigations and reduce the amount of money paid out on fraudulent
claims.
5. While tuning parameters for a classification algorithm, three different confusion matrices
were produced. For parameter p1, the confusion matrix is c1. For parameter p2, the
confusion matrix is c2. For parameter p3, the confusion matrix is c3. Explain how to draw
RoC curve and write the necessary equations. Using the RoC curve, determine the best
parameter among p1, p2, and p3. Show each of the steps clearly. [5]
Confusion Matrix c1
Predicted: No Predicted: Yes
Actual: No 500 100
Actual: Yes 50 1000
Confusion Matrix c2
Predicted: No Predicted: Yes
Actual: No 540 60
Actual: Yes 250 800
Confusion Matrix c3
Predicted: No Predicted: Yes
Actual: No 570 30
Actual: Yes 450 600
Solution:
For C1 : [0.5 + 0.5 marks]
TPR = 1000/1050 = 0.95
FPR = 100/600 = 0.17
For C2 : [0.5 + 0.5 marks]
TPR = 850/1050 = 0.76
FPR = 60/600 = 0.10
For C3 : [0.5 + 0.5 marks]
TPR = 600/1050 = 0.57
FPR = 30/600 = 0.05
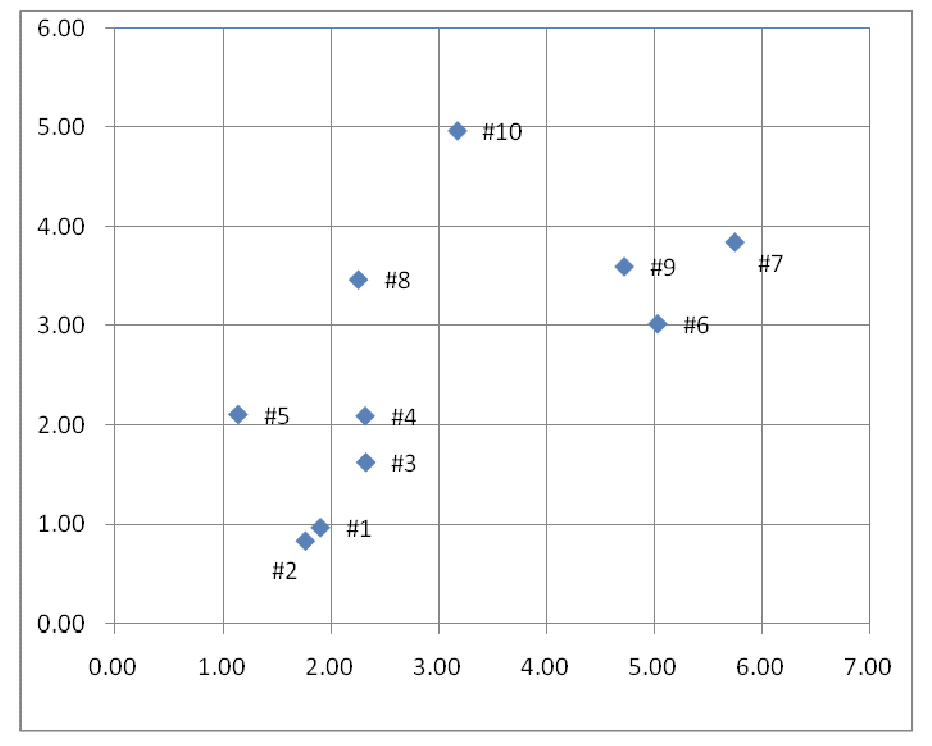
The red line is the reference line.
The point (0.17, 0.95) is far away from the red line.
Hence, p1 is the best parameter.
1 mark for the graph. 1 mark for the explanation.