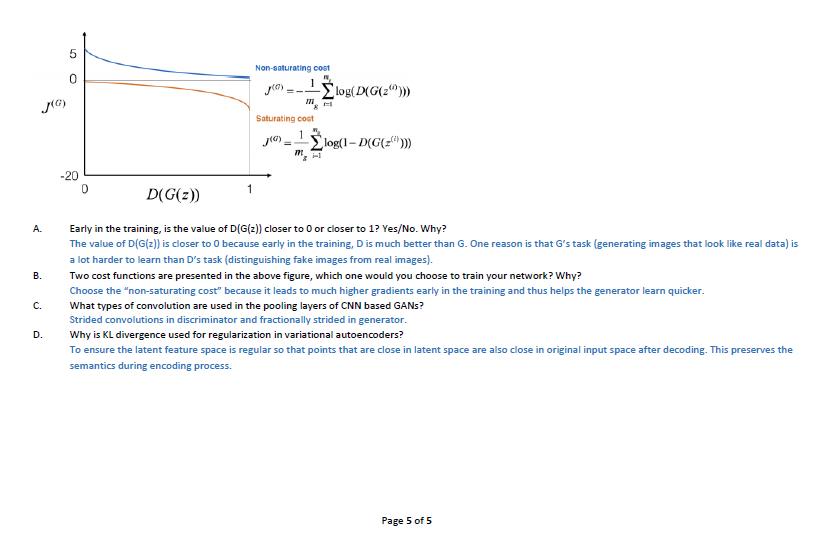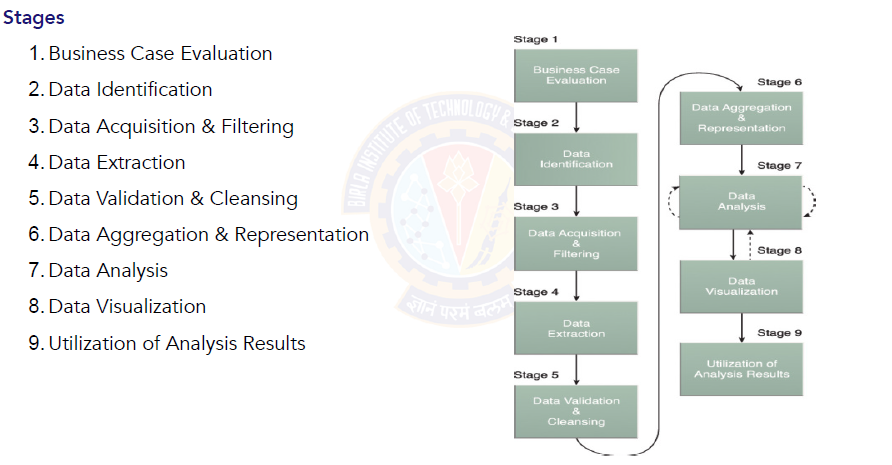
All the messages below are just forwarded messages if some one feels hurt about it please add your comments we will remove the post. Host/author is not responsible for these posts.

Hit + Miss = Total CPU ReferenceHit Ratio h = Hit / ( Hit + Miss )
Tavg = Average time to access memoryTavg = h * Tc + ( 1-h ) * ( Tm + Tc )



The tf-idf (term frequency-inverse document frequency) is a measure of the importance of a word in a document or a collection of documents. It is commonly used in information retrieval and natural language processing tasks.
The formula for calculating tf-idf is:
tf-idf = tf * idf
where:
tf (term frequency) is the frequency of the word in the document. It can be calculated as the number of times the word appears in the document divided by the total number of words in the document.
idf (inverse document frequency) is a measure of the rarity of the word. It can be calculated as the logarithm of the total number of documents divided by the number of documents that contain the word.
The resulting tf-idf score for a word reflects both the importance of the word in the specific document and its rarity in the collection of documents. Words that are common across all documents will have a lower tf-idf score, while words that are specific to a particular document and rare in the collection will have a higher tf-idf score.
----------------------------------
The tf-idf (term frequency-inverse document frequency) is a measure of the importance of a word in a document or a collection of documents. It is commonly used in information retrieval and natural language processing tasks.
The formula for calculating tf-idf is:
tf-idf = tf * idf
where:
tf (term frequency) is the frequency of the word in the document. It can be calculated as the number of times the word appears in the document divided by the total number of words in the document.
idf (inverse document frequency) is a measure of the rarity of the word. It can be calculated as the logarithm of the total number of documents divided by the number of documents that contain the word.
The resulting tf-idf score for a word reflects both the importance of the word in the specific document and its rarity in the collection of documents. Words that are common across all documents will have a lower tf-idf score, while words that are specific to a particular document and rare in the collection will have a higher tf-idf score.
----------------------