Web Crawler : It is a software for downloading pages from the Web. Also known as Web Spider, Web Robot, or simply Bot.
Web Crawler Applications
1.Create an index covering broad topics (General Web search )
2.Create an index covering specific topics (Vertical Web search )
3.Archive content :(Web archival, URL: http://www.archive.org/ )
4.Analyze Web sites for extracting aggregate statistics (Web characterization )
5.Keep copies or replicate Web sites (Web mirroring-daily or weekly)
6.Web site analysis (broken links, site not available)
Crawler Taxonomy

Basic Web Crawler Architecture
3 components in Web Crawler
Scheduler - Maintains a queue of URLS to Visit
downloader - downloads the pages
Storage - makes indexing of pages and provides scheduler with metadata on the pages retrieved

Crawling complications
1.Malicious Pages - spam pages & spider traps (crawler traps)
2.Non-malicious pages -
Latency / Bandwidth to remote servers vary
Webmasters stipulations -- how deep one has to crawl in a website.
3.Site mirrors and duplicate pages
4.Politness --> how frequently we should hit the server
Explicit politeness: specifications from webmasters on what portions of site can be crawled
robots.txt
Implicit politeness: even with no specification, avoid hitting any site too often
---------------------------------------------------------------------------------------------------------------------
Crawler should be distributed / scalable / performance & efficiency
fetch higher quality pages first
continuous operation -- fetch fresh copies of previous pages
Extensible : Adapt to new data formats.
robots.txt --> avoids overloading of the site.
----------------------------------------------------------------------------------------------------------------------
URL frontier
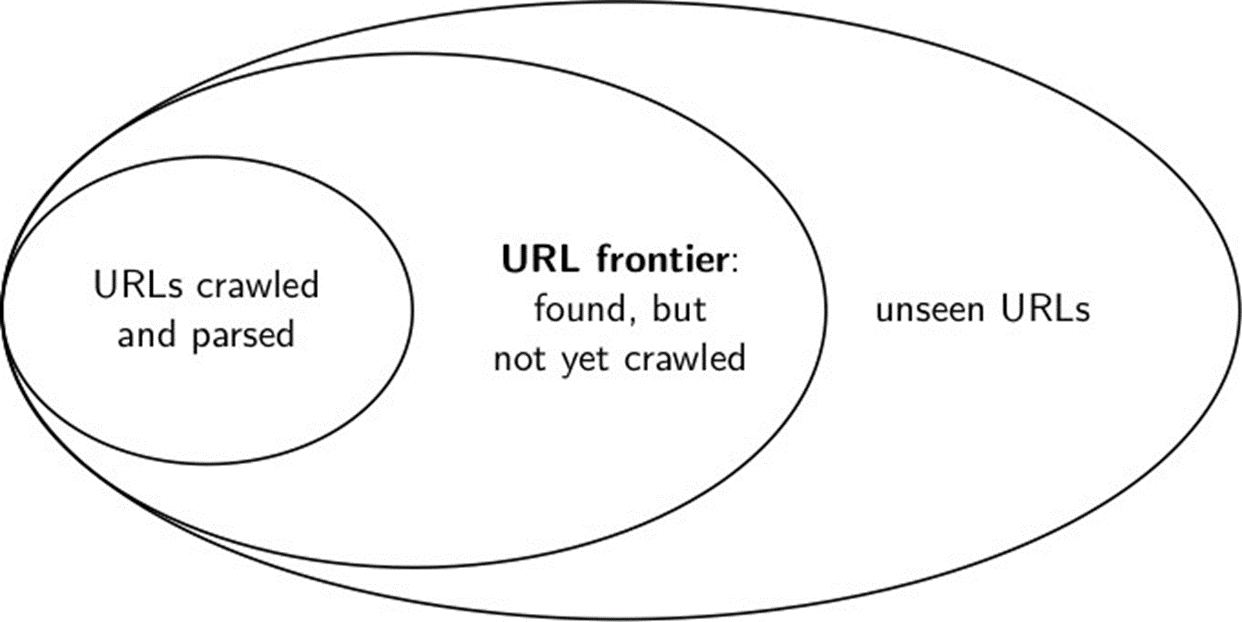
1.The URL frontier is the data structure that holds and manages URLs we’ve seen, but that have not been crawled yet.
2.Can include multiple pages from the same host
3.Must avoid trying to fetch them all at the same time
4.Must keep all crawling threads busy
Considerations
Politeness: do not hit a web server too frequently
Freshness: crawl some pages more often than others
-------------------------------------------------------------------------------------------------------------
Basic crawl architecture

-------------------------------------------------------------------------------------------------------------
All the messages below are just forwarded messages if some one feels hurt about it please add your comments we will remove the post. Host/author is not responsible for these posts.